Measuring Machine Learning Bias
Credit to Author: Dr. Supriya Ranjan Mitra| Date: Wed, 25 Sep 2019 08:31:08 +0000
Gartner estimates that by 2021, AI augmentation will generate $2.9 trillion in business value and recover 6.2 billion hours of worker productivity. 1 Yet, several recent surveys and studies have revealed that fewer than 1 in 4 people trust AI to make significant life decisions on their behalf. 2 The emergence and widespread usage of Machine Learning (ML) systems in a wide variety of applications, ranging from recruitment decisions to pretrial risk assessment, has raised concerns about their potential unfairness towards people with certain personas. Anti-discrimination laws in various countries prohibit unfair treatment of individuals based on sensitive attributes such as gender, race, etc. According to the Guardian – “Although neural networks might be said to write their own programs, they do so towards goals set by humans, using data collected for human purposes. If the data is skewed, even by accident, the computers will amplify injustice“. 3 As per a study done by Anupam Datta on Google Job Ads, the CMU professor ascertained that male job seekers were six times more likely to be shown Ads for high paying jobs than female job seekers. 4 Amazon decided to scrap its ML based recruitment engine in 2015, when it realized that the engine was not rating candidates for technical posts in a gender-neutral way. 5 James Zou (from Microsoft research) designed an algorithm to read and rank Web page relevance. Surprisingly, the engine would rank information from female programmers as less relevant than that from their male counterparts. 6 Researchers are now writing fairness guidelines into machine-learning algorithms to ensure that predictions and misclassifications for different groups are at equal rates. 7
The first step to managing fairness is to measure the same. We illustrate 3 different types of Bias measure with a hypothetical recruitment example below. In Table 1 – gender is a sensitive attribute, whereas the other two attributes (relevant experience and relevant education) are non-sensitive. We assume 3 male and 3 female candidates, and the √ / X indicates whether the candidates met the relevant non-sensitive criterion or not. Table 2 indicate actual decision on candidate selection by the interviewer. Table 3 indicate outcomes of three ML classifiers (C1, C2 and C3) on same candidates. Table 4 computes the presence/ absence of 3 types of classifier Bias as explained below.
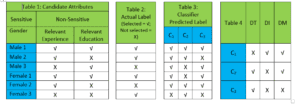
Disparate treatment (DT) arises when the classifier provides different outputs for groups of people with similar values of non-sensitive features but different values of sensitive features. In above example, Candidates Male 1 and Female 1 (also Male 2 and Female 2) have same non-sensitive attribute values for experience and education. However, the prediction of classifier C2 on Male 1 and Female 1 and classifier C3 on Male 2 and Female 2 is unfair.
Disparate Impact (DI) arises when the classifier provides outputs that benefit (hurt) a group of people. We deem classifier C1 as unfair due to disparate impact because the fraction of males and females that were hired are different (1.0 and 0.66 respectively).
Disparate mistreatment (DM) arises when classifier outputs have different misclassification rates for groups of people having different values of sensitive attribute. In our example, C1 and C2 are unfair because the rate of erroneous decisions for males and females are different: C1 has different false negative rates for males and females (0.0 and 0.5 respectively), whereas C2 has different false positive rates (0.0 and 1.0) as well as different false negative rates (0.0 and 0.5) for males and females.
As can be observed, both DT and DI have no dependency on Actual Labels – hence, they are appropriate where historical decisions are not reliable or trustworthy (for example in recruitment decisions). DM may be a preferred measure when the ground truth rationale for Actual Label decisions are explicable. An example would be pre-trial re-offence risk assessments for criminals (such as COMPAS classification used by State of Florida 8) where reliability of past sentencing terms can be elucidated by re-offence data from same criminals.

Despite growing concerns on ML Bias, efforts to curb the same is still insignificant. According to Nathan Srebro, computer scientist at the University of Chicago – “I’m not aware of any system either identifying or resolving discrimination that’s actively deployed in any application. Right now, it’s mostly trying to figure things out.” 7
#SchneiderElectric #LifeIsOn
References:
- https://www.gartner.com/document/3889586#dv_2_survey_ai
- https://www.govtech.com/biz/Survey-AI-Might-Have-an-Issue-With-Public-Trust.html
- https://www.theguardian.com/commentisfree/2016/oct/23/the-guardian-view-on-machine-learning-people-must-decide
- https://www.independent.co.uk/life-style/gadgets-and-tech/news/googles-algorithm-shows-prestigious-job-ads-to-men-but-not-to-women-10372166.html
- https://in.reuters.com/article/amazon-com-jobs-automation/insight-amazon-scraps-secret-ai-recruiting-tool-that-showed-bias-against-women-idINKCN1MK0AH
- https://www.technologyreview.com/s/602950/how-to-fix-silicon-valleys-sexist-algorithms/
- https://www.sciencenews.org/article/machines-are-getting-schooled-fairness
- https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing
The post Measuring Machine Learning Bias appeared first on Schneider Electric Blog.
http://blog.schneider-electric.com/feed/